Cache与Checkpoint
在Spark中需要Cache与Checkpoint机制的很重要原因是Spark的计算链(Computing chain | RDD Lineage)可能会很长,计算某些RDD也可能会花费很长的时间和消耗较多的资源,如果Task失败可能会导致整个计算链需要重新计算,因此采用Cache和Checkpoint机制可以保证访问重复数据可以很快的完成,同时也提高了容错性。
1. Cache机制
1.1 Cache策略
在Spark中,RDD可以在第一次计算得到的时候根据用户设定的Storage Level将各个Partition缓存到内存或磁盘,当下一次需要使用到该RDD时可以直接使用而不需要重新计算。目前Spark支持将RDD缓存到内存和磁盘,在缓存的时候也可以选择先进行序列化后在缓存,常用缓存策略如下表:
| Storage Level | Meaning |
|---|---|
| MEMORY_ONLY | 默认存储级别。将RDD存储在JVM堆(内存)中,如果内存不足,某些Partition可能不会被缓存,在需要时要重新计算 |
| MEMORY_AND_DISK | 将RDD存储在内存中,如果内存不足,剩余的部分存到磁盘中 |
| MEMORY_ONLY_SER (Java and Scala) | 以序列化的形式存储到内存中,不能存放的Partition在需要时对其进行重新计算 |
| MEMORY_AND_DISK_SER (Java and Scala) | 与MEMORY_ONLY_SER类似,但将不能存放到内存的Partition溢出到磁盘上 |
| DISK_ONLY | 只将RDD存放到磁盘 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc | 与对应的存储级别相似,不过集群中需要存储2份 |
| OFF_HEAP (experimental) | 与MEMORY_ONLY_SER类似,但是将数据存储在堆外存储器中,这需要启用堆外内存。 |
Spark 官方建议的采用的缓存策略:
- 尽量保持RDD的默认存储级别(MEMORY_ONLY),这是CPU效率最高的选项,允许RDD上的操作尽可能快地运行。
- 如果不是,可尝试使用MEMORY_ONLY_SER并选择一个快的序列化库,以使对象的空间效率更高,但访问速度仍然相当快,仅适用于Java和Scala API。
- 尽量不要将RDD缓存到磁盘,除非用于计算RDD非常消耗资源或者可以过滤掉大量数据。否则,重新计算分区的速度可能与从磁盘读取分区的速度一样快。
- 如果需要快速的故障恢复能力,使用复制的存储级别(XXX_2)。所有存储级别都通过重新计算丢失的数据来提供完全的容错能力,但是复制的存储级别具有冗余备份,一般情况下不需要等待重新计算丢失的分区。
1.2 Cache细节
通常情况下,被频繁地重复使用RDD需要进行Cache以提高效率。因为用户只能与Driver程序打交道,因此Cache一个RDD需要用户在编程的时候显式的调用rdd.cache() 或者rdd.persist(storagelevel)进行缓存。
用户只能cache程序代码中显式存在的rdd,对于那些Transformation中"隐式"生成的RDD,如ShuffledRDD,MapPartitionsRDD是不能被cache的。
-
缓存RDD Partition
Spark Cache RDD发生在第一次计算RDD时,在将要计算RDD Partition时(而不是已经计算得到一个record时),就去判断Partition是否需要被Cache,如果需要Cache的话,就先将Partition计算出来,然后缓存到内存。
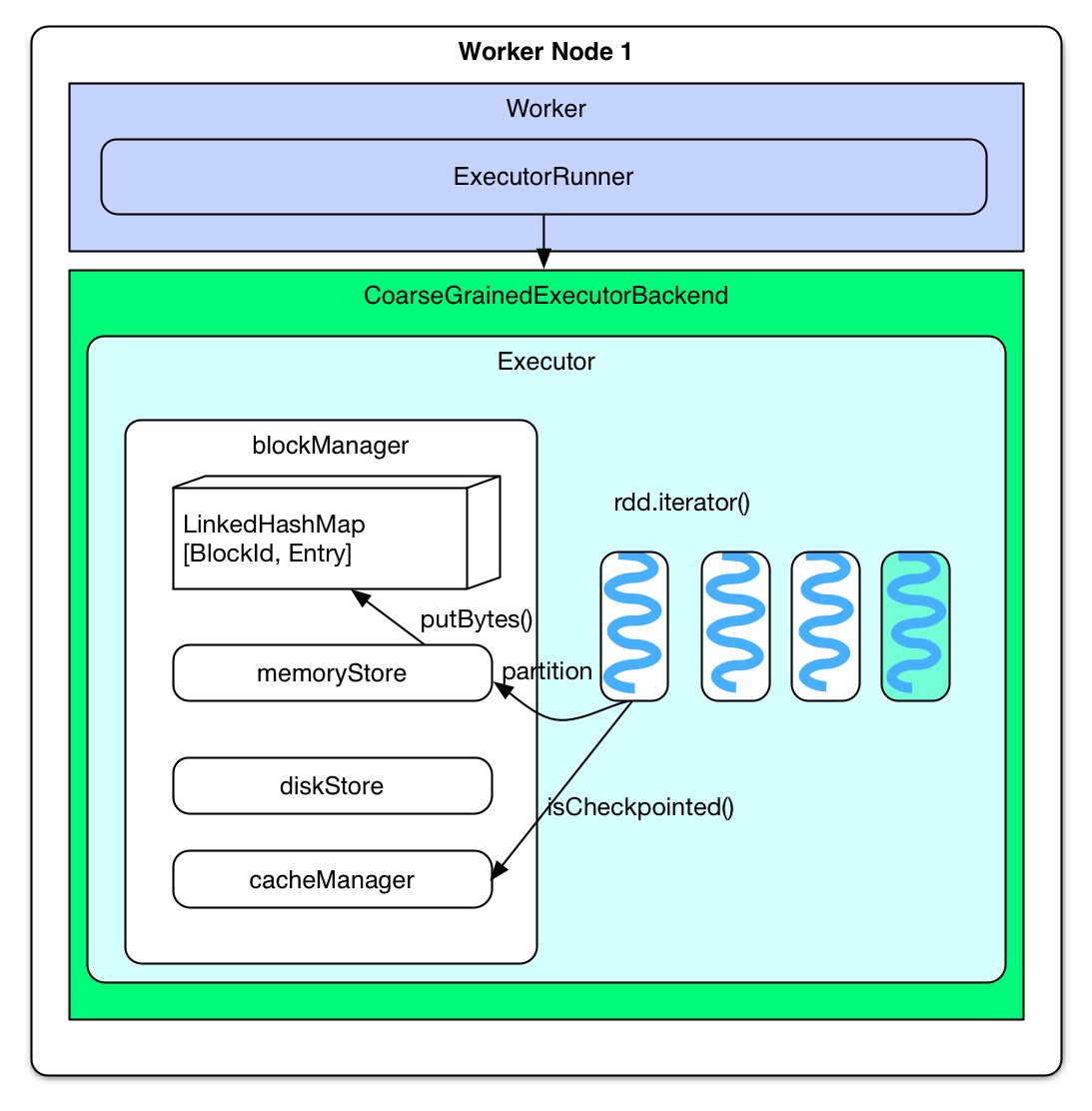
-
取cached RDD Partition
下次计算(一般是同一application 的下一个 job 计算)时如果用到 cached RDD,task 会直接去 blockManager 的 memoryStore 中读取。具体地讲,当要计算某个 rdd 中的 partition 时候(通过调用 rdd.iterator())会先去 blockManager 里 面查找是否已经被 cache 了,如果 partition 被 cache 在本地,就直接使用 blockManager.getLocal() 去本地 memoryStore 里读取。如果该 partition 被其他节点上 blockManager cache 了,会通过 blockManager.getRemote() 去其他节点上读取,读 取过程如下图。
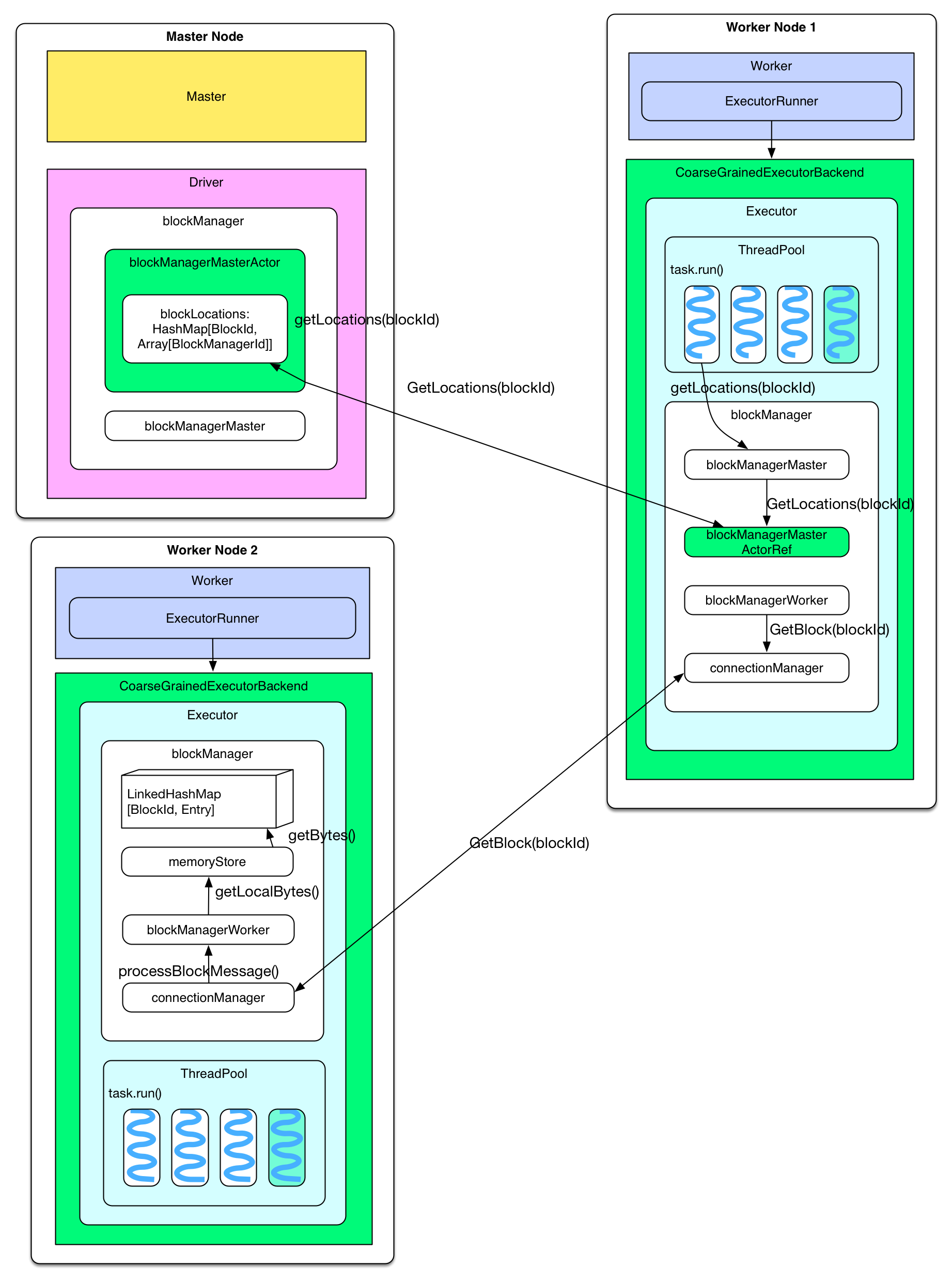
-
获取 cached partitions 的存储位置
partition 被 cache 后其所在节点上的 blockManager 会通知 driver 上的 blockMangerMasterActor 说某 rdd 的 partition 已经被我 cache 了,这个信息会存储在 blockMangerMasterActor 的 blockLocations: HashMap中。等到 task 执行需要 cached rdd 的时候,会调用 blockManagerMaster 的 getLocations(blockId) 去询问某 partition 的存储位置,这个询问信息会发到 driver 那里,driver 查询 blockLocations 获得位 置信息并将信息送回。 -
读取其他节点上的 cached partition task 得到 cached partition 的位置信息后,将 GetBlock(blockId) 的请求通过 connectionManager 发送到目标节点。目标节点收到请求后从本地 blockManager 那里的 memoryStore 读取 cached partition,最后发送回来。
-
2. Checkpoint机制
Spark中的Checkpoint机制是设计来对RDD进行持久化存储的(除非手动删除,否则它将永久存在于文件系统中,一般是缓存到HDFS中),因此可以跨Application使用,Cache机制中缓存到内存或磁盘中的RDD在application退出时就被清理掉了。
对于需要很长运算时间或运算量很大的rdd,computing chain过长或依赖其他rdd很多的rdd,可以选择对其进行Checkpoint。用户需要显式的调用rdd.checkpoint来对某个rdd设置检查点,sparkcontext.setCheckpointDir(dir)设置检查点目录。
2.1 Checkpoint细节
不同于Cache 机制是每计算出一个要 cache 的 partition 就直接将其 cache 到内存中,Checkpoint 机制是等到 job 结束后另外启动专门的 job 来完成 checkpoint 。也就是说需要 checkpoint 的 RDD 会被计算两次。因此,在使用 rdd.checkpoint() 的时候,建议加上 rdd.cache(),这样第二次运行的 job 就不用再去计算该 rdd ,而是直接读取 cache 后写磁盘。
RDD 需要经过 [ Initialized --> marked for checkpointing --> checkpointing in progress --> checkpointed ] 这几个阶段才能被 checkpoin。
-
Initialized
首先 driver program 需要使用rdd.checkpoint()去设定需要 checkpoint的rdd,检查点路径用sc.setCheckpointDir(dir)设置(一般设置HDFS目录),设定后该 rdd 就接受RDDCheckpointData管理。 -
marked for checkpointing
初始化后RDDCheckpointData会将管理的 rdd 标记为 MarkedForCheckpoint。 -
checkpointing in progress
每个 job 运行结束后Spark会调用finalRdd.doCheckpoint(),finalRdd 会顺着 computing chain 回溯扫描,碰到要 checkpoint 的 RDD 就将其标记为CheckpointingInProgress,然后将写磁盘(比如写 HDFS)需要的配置文件 (如 core-site.xml 等)broadcast 到其他 worker 节点上的 blockManager。完成以后,启动一个 job 来完成 checkpoint(使 用rdd.context.runJob(rdd, CheckpointRDD.writeToFile(path.toString, broadcastedConf)))。 -
checkpointed job 完成 checkpoint 后,将该 rdd 的 dependency 全部清掉,并设定该 rdd 状态为 checkpointed。然后为该 rdd 强加一个依赖,设置该 rdd 的 parent rdd 为
CheckpointRDD,该 CheckpointRDD 负责以后读取在文件系统上的 checkpoint 文件,生成该 rdd 的 partition。
当调用 rdd.iterator() 去计算该 rdd 的 partition 的时候,会调用 computeOrReadCheckpoint(split: Partition) 去查看该 rdd 是 否被 checkpoint 过了,如果是,就调用该 rdd 的 parent rdd 的 iterator() 也就是 CheckpointRDD.iterator(),CheckpointRDD 负责读取文件系统上的文件,生成该 rdd 的 partition。
3. Cache与Checkpoint的异同
- Cache机制中RDD Partition被缓存到内存或磁盘(或内存+磁盘),数据由blockManager管理。
- Application退出后Cache在磁盘/内存中的RDD Partition会被清空。
- Cache不会破坏RDD的Lineage,即RDD Partition丢失后可以根据计算链重新计算。
- 需要cache的 RDD 是在第一次计算得到时以Partition为单位进行缓存的。
- Checkpoint机制中RDD Partition被持久化存储到文件系统(一般是HDFS)。
- Application退出后Checkpoint的数据依旧存在,可以被其他应用使用。
- Checkpoint会将RDD的依赖关系完全清除,并强加一个Parent RDD
CheckpointRDD,需要时只能用CheckpointRDD从文件系统中读取数据,如果存储在文件系统上的数据被蓄意破坏,则需要重新启动该Application才能恢复计算。 - Checkpoint发生在当前job结束后重新启动一个新的job来完成检查点的存储工作。
Reference: